The goal of this notebook is to provide an analysis of the time-series data from a user of a fitbit tracker throughout a year. I will use this data to predict an additional year of the life of the user using Generalized Additive Models.
Packages used:
- pandas, numpy, matplotlib, seaborn
- Prophet
import pandas as pd
import numpy as np
from fbprophet import Prophet
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
Data cleaning (missing data and outliers)
# import the activity data
activity = pd.read_csv('OneYearFitBitData.csv')
# change commas to dots
activity.iloc[:,1:] = activity.iloc[:,1:].applymap(lambda x: float(str(x).replace(',','.')))
# change column names to English
activity.columns = ['Date', 'BurnedCalories', 'Steps', 'Distance', 'Floors', 'SedentaryMinutes', 'LightMinutes', 'ModerateMinutes', 'IntenseMinutes', 'IntenseActivityCalories']
# import the sleep data
sleep = pd.read_csv('OneYearFitBitDataSleep.csv')
# check the size of the dataframes
activity.shape, sleep.shape
# merge dataframes
data = pd.merge(activity, sleep, how='outer', on='Date')
# parse date into correct format
data['Date'] = pd.to_datetime(data['Date'], format='%d-%m-%Y')
# correct units for Calories and Steps
for c in ['BurnedCalories', 'Steps', 'IntenseActivityCalories']:
data[c] = data[c]*1000
Once imported, we should check for any missing data:
# check for missing data
data.isnull().sum()
Date 0
BurnedCalories 0
Steps 0
Distance 0
Floors 0
SedentaryMinutes 0
LightMinutes 0
ModerateMinutes 0
IntenseMinutes 0
IntenseActivityCalories 0
MinutesOfSleep 5
MinutesOfBeingAwake 5
NumberOfAwakings 5
LengthOfRestInMinutes 5
dtype: int64
# check complete rows where sleep data is missing
data.iloc[np.where(data['MinutesOfSleep'].isnull())[0],:]
| Date | Burned Calories | Steps | Distance | Floors | Sedentary Minutes | Light Minutes | Moderate Minutes |
|---|---|---|---|---|---|---|---|
| 2015-05-08 | 1934.0 | 905000.0 | 0.65 | 0.0 | 1.355 | 46.0 | 0.0 |
| 2016-02-01 | 2986.0 | 11426.0 | 8.52 | 12.0 | 911.000 | 192.0 | 48.0 |
| 2016-02-02 | 2974.0 | 10466.0 | 7.78 | 13.0 | 802.000 | 152.0 | 48.0 |
| 2016-02-03 | 3199.0 | 12866.0 | 9.63 | 11.0 | 767.000 | 271.0 | 45.0 |
| 2016-02-04 | 2037.0 | 2449.0 | 1.87 | 0.0 | 821.000 | 80.0 | 0.0 |
| Date | Intense Minutes | Intense Activity Calories | Minutes Of Sleep | Minutes Of Being Awake | Number Of Awakings | Length Of Rest In Minutes |
|---|---|---|---|---|---|---|
| 2015-05-08 | 0.0 | 168000.0 | NaN | NaN | NaN | NaN |
| 2016-02-01 | 43.0 | 1478.0 | NaN | NaN | NaN | NaN |
| 2016-02-02 | 48.0 | 1333.0 | NaN | NaN | NaN | NaN |
| 2016-02-03 | 28.0 | 1703.0 | NaN | NaN | NaN | NaN |
| 2016-02-04 | 0.0 | 337000.0 | NaN | NaN | NaN | NaN |
We can see that the sleep information was missing for some dates. The activity information for those days is complete. Therefore, we should not get rid of those rows just now.
# check rows for which steps count is zero
data.iloc[np.where(data['Steps']==0)[0],:]
| Date | Burned Calories | Steps | Distance | Floors | Sedentary Minutes | Light Minutes | Moderate Minutes |
|---|---|---|---|---|---|---|---|
| 2015-12-23 | 1789.0 | 0.0 | 0.0 | 0.0 | 1.44 | 0.0 | 0.0 |
| 2016-03-13 | 1790.0 | 0.0 | 0.0 | 0.0 | 1.44 | 0.0 | 0.0 |
| 2016-03-28 | 1790.0 | 0.0 | 0.0 | 0.0 | 1.44 | 0.0 | 0.0 |
| Date | Intense Minutes | Intense Activity Calories | Minutes Of Sleep | Minutes Of Being Awake | Number Of Awakings | Length Of Rest In Minutes |
|---|---|---|---|---|---|---|
| 2015-12-23 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2016-03-13 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2016-03-28 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
We can also see that the step count for some datapoints is zero. If we look at the complete rows, we can see that on those days nearly no other data was recorded. I assume that the user probably did not wear the fitness tracker on that day and we could get rid of those complete rows.
# drop days with a step count of zero
data = data.drop(np.where(data['Steps']==0)[0], axis=0)
# plot the distribution of data for step count
sns.distplot(data['Steps'])
plt.title('Histogram for step count')
<matplotlib.text.Text at 0x10fb34cc0>
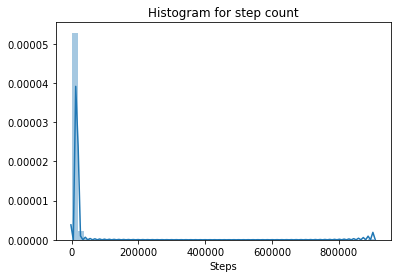
Step count is probably the most accurate measure obtained from a pedometer. Looking at the distribution of this variable, however, we can see that there is a chance that we have outliers in the data, as at least one value seems to be much higher than all the rest.
# sort data by step count in a descending order
data.sort_values(by='Steps', ascending=False).head()
| Date | Burned Calories | Steps | Distance | Floors | Sedentary Minutes | Light Minutes | Moderate Minutes |
|---|---|---|---|---|---|---|---|
| 2015-05-08 | 1934.0 | 905000.0 | 0.65 | 0.0 | 1.355 | 46.0 | 0.0 |
| 2016-01-24 | 1801.0 | 39000.0 | 0.03 | 0.0 | 1.076 | 5.0 | 0.0 |
| 2015-06-13 | 4083.0 | 26444.0 | 19.65 | 22.0 | 549.000 | 429.0 | 56.0 |
| 2016-04-28 | 4030.0 | 25571.0 | 19.30 | 15.0 | 606.000 | 293.0 | 42.0 |
| 2016-03-16 | 3960.0 | 25385.0 | 20.45 | 17.0 | 638.000 | 254.0 | 17.0 |
| Date | Intense Minutes | Intense Activity Calories | Minutes Of Sleep | Minutes Of Being Awake | Number Of Awakings | Length Of Rest In Minutes |
|---|---|---|---|---|---|---|
| 2015-05-08 | 0.0 | 168000.0 | NaN | NaN | NaN | NaN |
| 2016-01-24 | 0.0 | 16000.0 | 342.0 | 48.0 | 31.0 | 390.0 |
| 2015-06-13 | 56.0 | 2818.0 | 169.0 | 20.0 | 11.0 | 196.0 |
| 2016-04-28 | 129.0 | 2711.0 | 374.0 | 56.0 | 34.0 | 430.0 |
| 2016-03-16 | 124.0 | 2556.0 | 368.0 | 46.0 | 22.0 | 414.0 |
We found the outlier! It seems that the step count for the first day (our data starts on May 8th, 2015) is too high to be a correct value for the amount of steps taken by the user on that day. Maybe the device saves the vibration since its production as step count which is loaded on the first day that the user wears the tracker. We can anyway get rid of that row since the sleep data is also not available for this day.
# drop outlier
data = data.drop(np.where(data['Steps']>=100000)[0], axis=0)
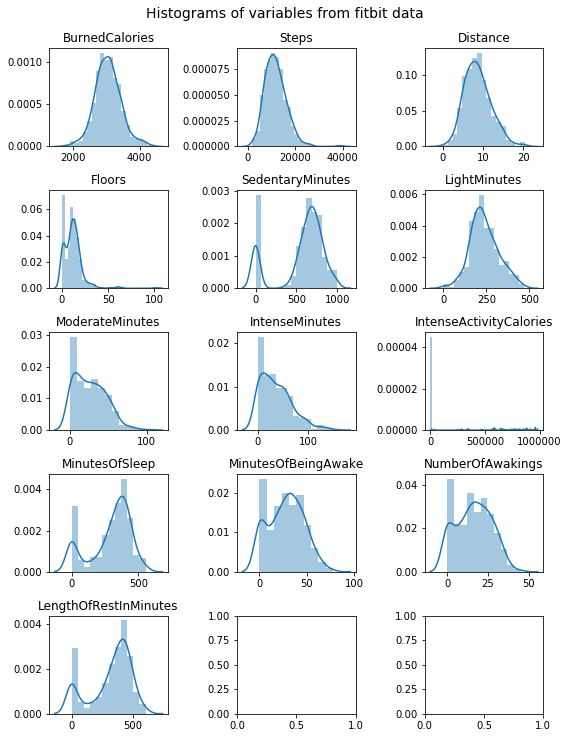
Now we can look at our preprocessed data. Shape, distribution of the variables, and a look at some rows from the dataframe, are all useful things to observe:
data.shape
(369, 14)
fig, ax = plt.subplots(5,3, figsize=(8,10))
for c, a in zip(data.columns[1:], ax.flat):
df = pd.DataFrame()
df['ds'] = data['Date']
df['y'] = data[c]
df = df.dropna(axis=0, how='any')
sns.distplot(df['y'], axlabel=False, ax=a)
a.set_title(c)
plt.suptitle('Histograms of variables from fitbit data', y=1.02, fontsize=14);
plt.tight_layout()
data.head()
| Date | Burned Calories | Steps | Distance | Floors | Sedentary Minutes | Light Minutes | Moderate Minutes |
|---|---|---|---|---|---|---|---|
| 2015-05-09 | 3631.0 | 18925.0 | 14.11 | 4.0 | 611.0 | 316.0 | 61.0 |
| 2015-05-10 | 3204.0 | 14228.0 | 10.57 | 1.0 | 602.0 | 226.0 | 14.0 |
| 2015-05-11 | 2673.0 | 6756.0 | 5.02 | 8.0 | 749.0 | 190.0 | 23.0 |
| 2015-05-12 | 2495.0 | 5020.0 | 3.73 | 1.0 | 876.0 | 171.0 | 0.0 |
| 2015-05-13 | 2760.0 | 7790.0 | 5.79 | 15.0 | 726.0 | 172.0 | 34.0 |
| Date | Intense Minutes | Intense Activity Calories | Minutes Of Sleep | Minutes Of Being Awake | Number Of Awakings | Length Of Rest In Minutes |
|---|---|---|---|---|---|---|
| 2015-05-09 | 60.0 | 2248.0 | 384.0 | 26.0 | 23.0 | 417.0 |
| 2015-05-10 | 77.0 | 1719.0 | 454.0 | 35.0 | 21.0 | 491.0 |
| 2015-05-11 | 4.0 | 962000.0 | 387.0 | 46.0 | 25.0 | 436.0 |
| 2015-05-12 | 0.0 | 736000.0 | 311.0 | 31.0 | 21.0 | 350.0 |
| 2015-05-13 | 18.0 | 1094.0 | 407.0 | 65.0 | 44.0 | 491.0 |
Predicting the step count for an additional year
In order to use the Prophet package to predict the future using a Generalized Additive Model, we need to create a dataframe with columns ds and y (we need to do this for each variable):
dsis the date stamp data giving the time componentyis the variable that we want to predict
In our case we will use the log transform of the step count in order to decrease the effect of outliers on the model.
df = pd.DataFrame()
df['ds'] = data['Date']
df['y'] = data['Steps']
# log-transform of step count
df['y'] = np.log(df['y'])
Now we need to specify the type of growth model that we want to use:
- Linear: assumes that the variable
ygrows linearly in time (doesn’t apply to our step count scenario, if the person sticks to their normal lifestyle) - Logistic: assumes that the variable
ygrows logistically in time and saturates at some point
I will assume that the person, for whom we want to predict the step count in the following year, will not have any dramatic lifestyle changes that makes them start to walk more. Therefore, I am using logistic ‘growth’ capped to a cap of the mean of the data, which in practice means that the step count’s growth trend will be ‘zero growth’.
df['cap'] = df['y'].median()
m = Prophet(growth='logistic', yearly_seasonality=True)
m.fit(df)
INFO:fbprophet.forecaster:Disabling daily seasonality. Run prophet with daily_seasonality=True to override this.
/Users/dario/anaconda/envs/datasci/lib/python3.6/site-packages/pystan/misc.py:399: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.
elif np.issubdtype(np.asarray(v).dtype, float):
<fbprophet.forecaster.Prophet at 0x115274dd8>
After fitting the model, we need a new dataframe future with the additional rows for which we want to predict y.
future = m.make_future_dataframe(periods=365, freq='D')
future['cap'] = df['y'].median()
Now we can call predict on the fitted model and obtain relevant statistics for the forecast period. We can also plot the results.
forecast = m.predict(future)
forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail()
| ds | yhat | yhat_lower | yhat_upper | |
|---|---|---|---|---|
| 729 | 2017-05-03 | 9.565727 | 9.109546 | 10.034228 |
| 730 | 2017-05-04 | 9.547910 | 9.089434 | 10.038742 |
| 731 | 2017-05-05 | 9.536875 | 9.084160 | 10.035884 |
| 732 | 2017-05-06 | 9.525034 | 9.068735 | 10.008784 |
| 733 | 2017-05-07 | 9.289238 | 8.792235 | 9.746812 |
m.plot(forecast, ylabel='log(Steps)', xlabel='Date');
plt.title('1-year prediction of step count from 1 year of fitbit data');
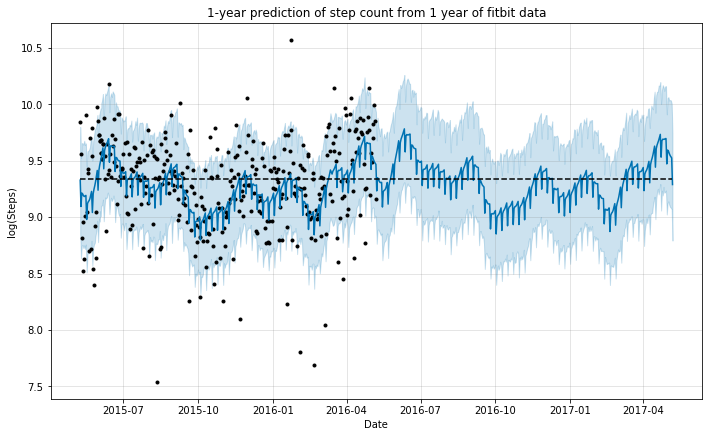
We can see that the model did a good job in mimicking the behavior of step count during the year for which the data was available. This seems reasonable, as we do not expect the pattern to vary necessarily, if the person continues to have a similar lifestyle.
Additionally, we can plot the components from the Generalized Additive Model and see their effect on the ‘y’ variable. In this case we have the general trend (remember we capped this at ‘10’), the yearly seasonality effect, and the weekly effect.
m.plot_components(forecast);
plt.suptitle('GAM components for prediction of step count', y=1.02, fontsize=14);
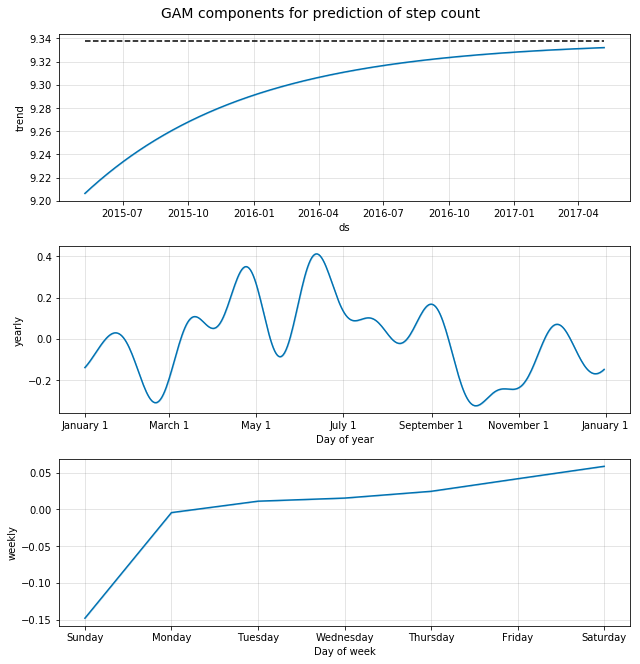
Here we see some interesting patterns:
- The general ‘growth’ trend is as expected, as we assumed that there would be no growth beyond the mean of the existing data.
- The yearly effect shows a trend towards higher activity during the summer months, however the variation is considerable, probably due to the fact that our dataset consisted of the data for one year only
- The weekly effect shows that Sunday is a day of lower activity for this person whereas Saturday is the day where the activity is the highest. So, grocery shopping on Saturday, Netflix on Sunday? :)
Sleep analysis
A very important part of our lives is sleep. It would be very interesting to look at the sleep habits of the user of the fitness tracker and see if we can get some insights from this data.
df = pd.DataFrame()
df['ds'] = data['Date']
df['y'] = data['MinutesOfSleep']
df = df.dropna(axis=0, how='any')
# drop rows where sleep time is zero, as this would mean that the person did not wear the tracker overnight and the data is missing
df = df.iloc[np.where(df['y']!=0)[0],:]
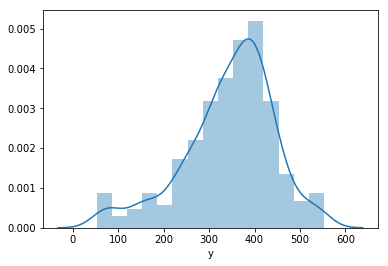
# distribution of MinutesOfSleep
sns.distplot(df['y'])
<matplotlib.axes._subplots.AxesSubplot at 0x1163770f0>
df['cap'] = df['y'].median()
m = Prophet(growth='logistic', yearly_seasonality=True)
m.fit(df)
future = m.make_future_dataframe(periods=365, freq='D')
future['cap'] = df['y'].median()
forecast = m.predict(future)
m.plot(forecast);
plt.title('1-year prediction of MinutesOfSleep from 1 year of fitbit data');
INFO:fbprophet.forecaster:Disabling daily seasonality. Run prophet with daily_seasonality=True to override this.
/Users/dario/anaconda/envs/datasci/lib/python3.6/site-packages/pystan/misc.py:399: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.
elif np.issubdtype(np.asarray(v).dtype, float):
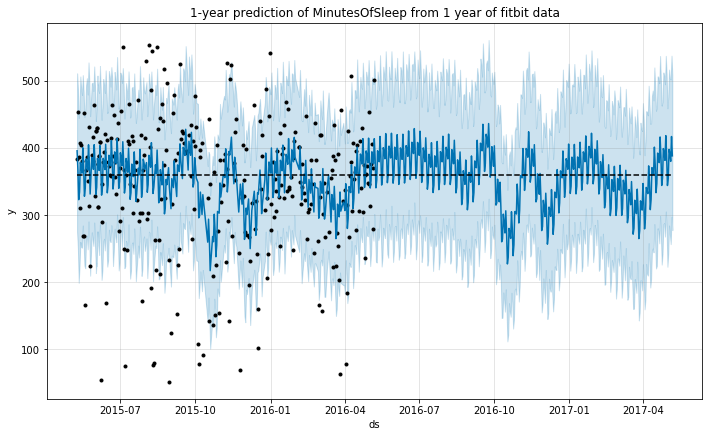
The model again seems to predict a similar sleep behavior for the predicted year. This seems reasonable, as we do not expect the pattern to vary necessarily, if the person continues to have a similar lifestyle.
m.plot_components(forecast);
plt.suptitle('GAM components for prediction of MinutesOfSleep', y=1.02, fontsize=14);
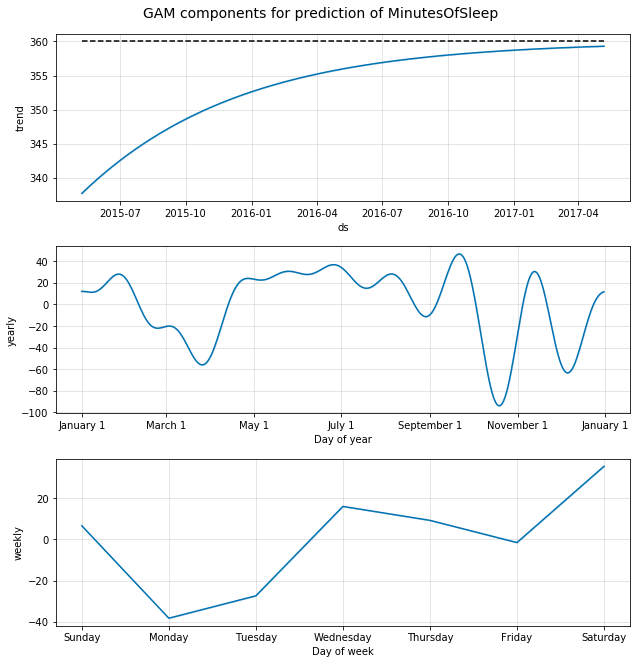
A look at the amount of sleep reveals:
- A saturation trend at the median (we set this assumption)
- A yearly effect shows a trend towards higher amount of sleep during the summer months, with more variation during winter
- The weekly effect shows lowest sleep amount on Mondays (maybe going to bed late on Sunday and waking up early on Monday is a pattern for this user). Highest amout of sleep occurs on Saturdays (no alarm to wake up to on Saturday morning!). Interestingly, the user seems to get more sleep on Wednesdays than on Mondays or Tuesdays, which could mean that their work schedule is not constant during week-days.
Appendix
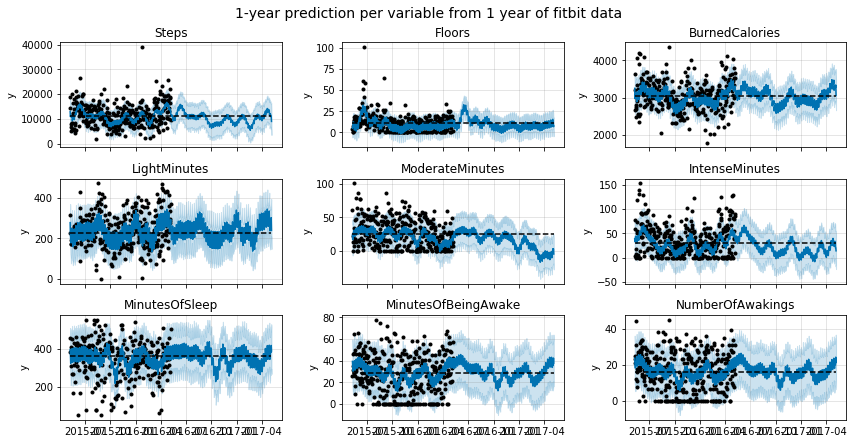
As an exercise, I have plotted the predictions for the most interesing variables in the dataset. Enjoy!
zeros_allowed = ['Floors', 'SedentaryMinutes', 'LightMinutes', 'ModerateMinutes', 'IntenseMinutes', 'IntenseActivityCalories', 'MinutesOfBeingAwake', 'NumberOfAwakings']
fig, ax = plt.subplots(3,3, figsize=(12,6), sharex=True)
predict_cols = ['Steps', 'Floors', 'BurnedCalories', 'LightMinutes', 'ModerateMinutes', 'IntenseMinutes', 'MinutesOfSleep', 'MinutesOfBeingAwake', 'NumberOfAwakings']
for c, a in zip(predict_cols, ax.flat):
df = pd.DataFrame()
df['ds'] = data['Date']
df['y'] = data[c]
df = df.dropna(axis=0, how='any')
if c not in zeros_allowed:
df = df.iloc[np.where(df['y']!=0)[0],:]
df['cap'] = df['y'].median()
m = Prophet(growth='logistic', yearly_seasonality=True)
m.fit(df)
future = m.make_future_dataframe(periods=365, freq='D')
future['cap'] = df['y'].median()
future.tail()
forecast = m.predict(future)
forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail()
m.plot(forecast, xlabel='', ax=a);
a.set_title(c)
#m.plot_components(forecast);
plt.suptitle('1-year prediction per variable from 1 year of fitbit data', y=1.02, fontsize=14);
plt.tight_layout()
INFO:fbprophet.forecaster:Disabling daily seasonality. Run prophet with daily_seasonality=True to override this.
/Users/dario/anaconda/envs/datasci/lib/python3.6/site-packages/pystan/misc.py:399: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.
elif np.issubdtype(np.asarray(v).dtype, float):
INFO:fbprophet.forecaster:Disabling daily seasonality. Run prophet with daily_seasonality=True to override this.
INFO:fbprophet.forecaster:Disabling daily seasonality. Run prophet with daily_seasonality=True to override this.
INFO:fbprophet.forecaster:Disabling daily seasonality. Run prophet with daily_seasonality=True to override this.
INFO:fbprophet.forecaster:Disabling daily seasonality. Run prophet with daily_seasonality=True to override this.
INFO:fbprophet.forecaster:Disabling daily seasonality. Run prophet with daily_seasonality=True to override this.
INFO:fbprophet.forecaster:Disabling daily seasonality. Run prophet with daily_seasonality=True to override this.
INFO:fbprophet.forecaster:Disabling daily seasonality. Run prophet with daily_seasonality=True to override this.
INFO:fbprophet.forecaster:Disabling daily seasonality. Run prophet with daily_seasonality=True to override this.