
I am currently reading Probabilistic Programming & Bayesian Methods for Hackers, to upskill myself on Bayesian experiments. After going through the authors examples, I was curious to try it on a dataset and problem I was already familiar with: predicting IPF disease progression, considering the uncertainty of the preditions.
The OSIC Pulmonary Fibrosis Progression, 2020 challenged kagglers to predict lung function decline by using AI and machine learning. The problem seem to lend iself to a Bayesian approach, because for each FVC measurement also a confidence measure for the prediction was asked.
For this article, I forked and adapted the following kernel: https://www.kaggle.com/carlossouza/bayesian-experiments. I would like to thank Carlos for sharing this great piece of work with the kaggle community!
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.preprocessing import LabelEncoder
import numpy as np
import scipy.stats as stats
import warnings
import matplotlib.cbook
warnings.filterwarnings("ignore")
import pymc3 as pm
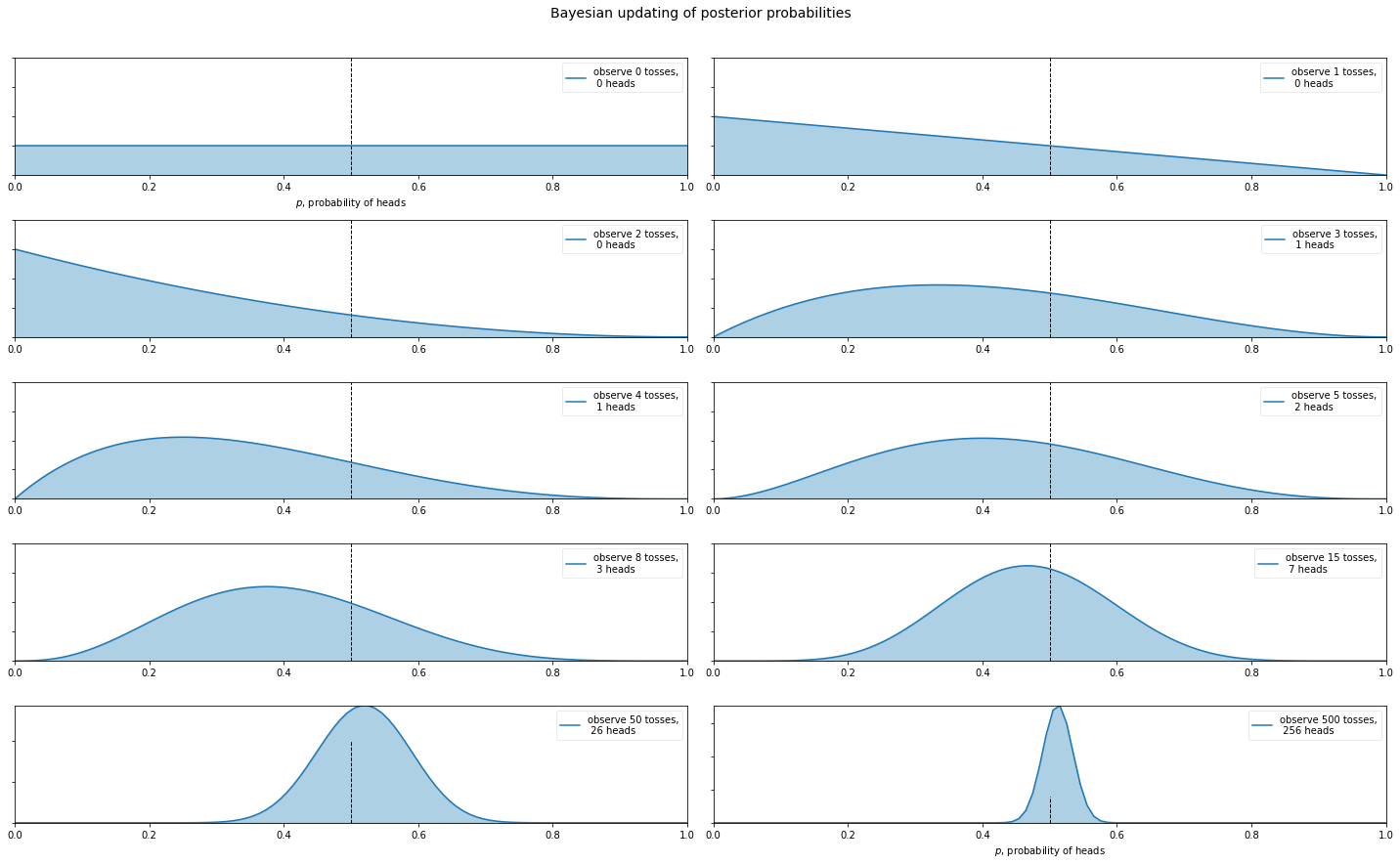
Bayesian Posterior Probabilities - Coin Flipping Example
So what are Bayesian Posterior Probabilities? Let’s start with an example everyone knows: coin flipping.
plt.rcParams["figure.figsize"] = (20,12)
dist = stats.beta
n_trials = [0, 1, 2, 3, 4, 5, 8, 15, 50, 500]
data = stats.bernoulli.rvs(0.5, size=n_trials[-1])
x = np.linspace(0, 1, 100)
# For the already prepared, I'm using Binomial's conj. prior.
for k, N in enumerate(n_trials):
sx = plt.subplot(len(n_trials)/2, 2, k+1)
plt.xlabel("$p$, probability of heads") \
if k in [0, len(n_trials)-1] else None
plt.setp(sx.get_yticklabels(), visible=False)
heads = data[:N].sum()
y = dist.pdf(x, 1 + heads, 1 + N - heads)
plt.plot(x, y, label="observe %d tosses,\n %d heads" % (N, heads))
plt.fill_between(x, 0, y, color="#348ABD", alpha=0.4)
plt.vlines(0.5, 0, 4, color="k", linestyles="--", lw=1)
leg = plt.legend()
leg.get_frame().set_alpha(0.4)
plt.autoscale(tight=True)
plt.suptitle("Bayesian updating of posterior probabilities",
y=1.02,
fontsize=14)
plt.tight_layout()
Bayesian and Frequentist Linear Regression
In general, frequentists think about Linear Regression as follows:
where Y is the output we want to predict (or dependent variable), X is our predictor (or independent variable), α and β are the coefficients (or parameters) of the model we want to estimate. ε is an error term which is assumed to be normally distributed. We can then use Ordinary Least Squares or Maximum Likelihood to find the best fitting β.
Bayesians take a probabilistic view of the world and express this model in terms of probability distributions. Our above linear regression can be rewritten to yield:
In words, we view Y as a random variable (or random vector) of which each element (data point) is distributed according to a Normal distribution. The mean of this normal distribution is provided by our linear predictor with variance var.
While this is essentially the same model, there are two critical advantages of Bayesian estimation:
- Priors: We can quantify any prior knowledge we might have by placing priors on the paramters. For example, if we think that σ is likely to be small we would choose a prior with more probability mass on low values.
- Quantifying uncertainty: We do not get a single estimate of β as above but instead a complete posterior distribution about how likely different values of β are. For example, with few data points our uncertainty in β will be very high and we’d be getting very wide posteriors.
1. A simpler way to look at the data
In classic machine learning we often think the more data the better and regualarization will anyway surpress noise in the features being used. In Bayesian Modelling we are usually more thoughtful on what to include in the analysis and try to justify the the inclusion and exclusion of features.
FVC (Forced Vital Capacity)is a measurement of lung function. The key idea here is to train a model on the trajectory of lung function decline, informing the model who the patients are, meaniong identifying the owner of each data point.
But informing the model about who the patients are wouldn’t be a form of data leakage? No, that’s not the case. We must inform the model who the patients are. That’s because the data points are NOT independent. FVC measures from a given patient are strongly correlated. We should not discard that information, it is too valuable. A model might learn to appropriately group patients by inferring the stage of the disease, only by being fed with the FVC decline curves from each patient (with several missing values!).
To prove that this approach works (and actually produces good results!), in the first model we will use only:
- FVC
- Week
- Patient ID
You might argue it will be “easy” for a model to predict future FVC measures once it is trained with several past FVC measures from a given patient. So, we will make it harder: we will remove all data points from the 5 test patients from the training set, except the first baseline FVC measurement. This means that our model will have only a single point from these 5 patients to use in order to generate future FVC predictions.
exclude_test_patient_data_from_trainset = True
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
if exclude_test_patient_data_from_trainset:
train = train[~train['Patient'].isin(test['Patient'].unique())]
train = pd.concat([train, test], axis=0, ignore_index=True)\
.drop_duplicates()
le_id = LabelEncoder()
train['PatientID'] = le_id.fit_transform(train['Patient'])
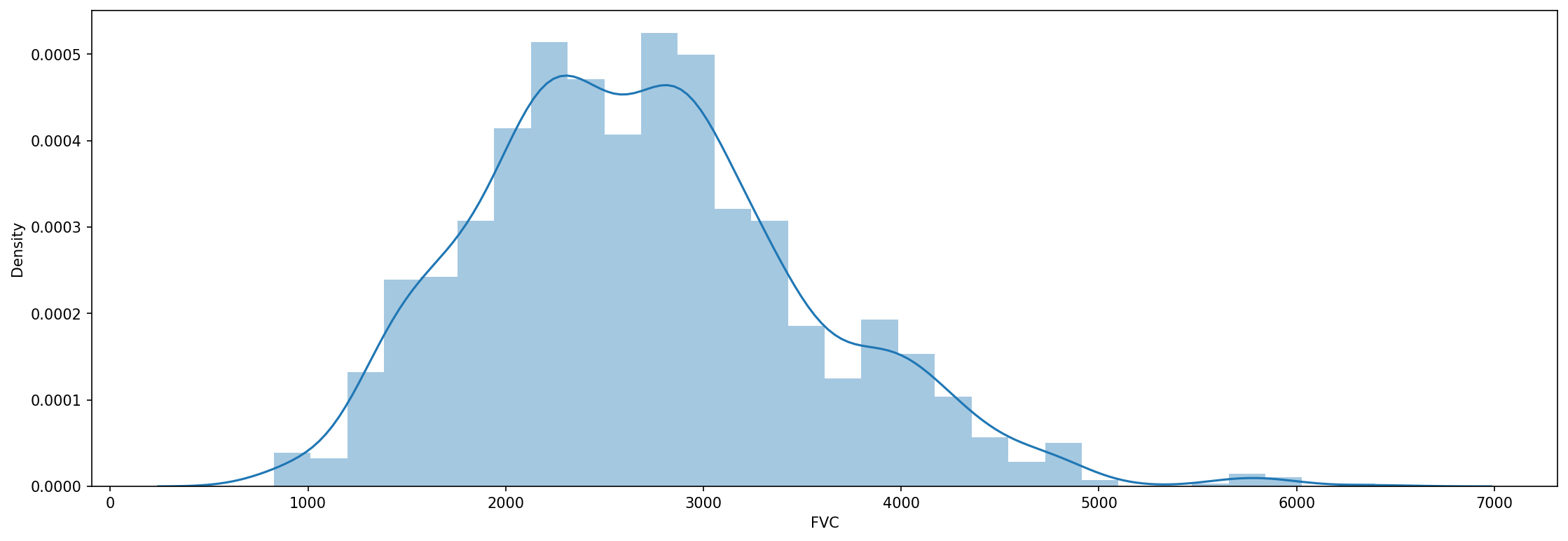
And for now, that’s all there is to data pre-processing! We can again just inspect the FVC declines:
fig, axes = plt.subplots(ncols=1, figsize=(18, 6), dpi=150)
sns.distplot(train['FVC'], label='FVC', ax=axes);
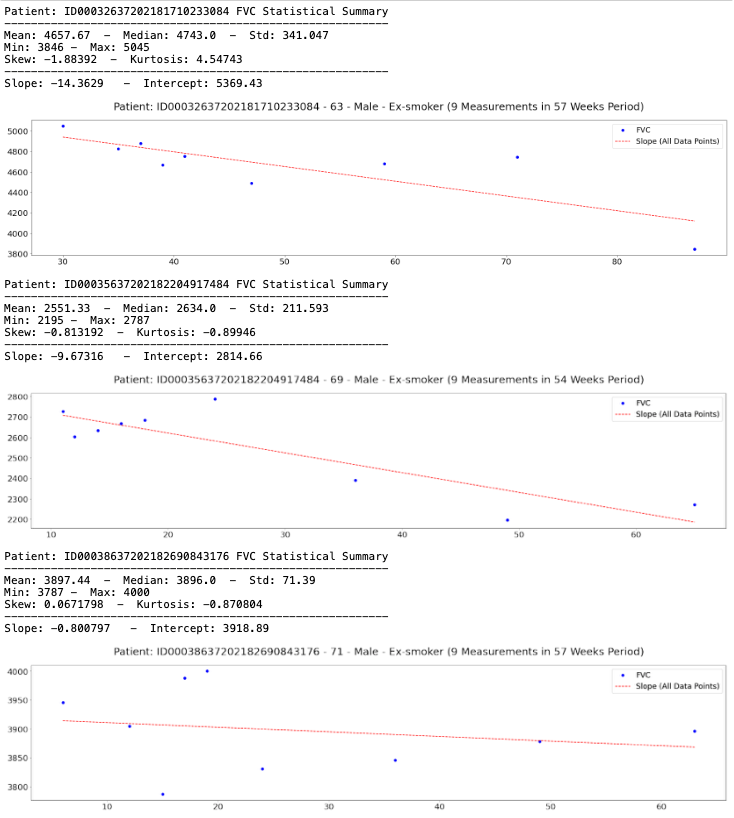
show_patients = ['ID00032637202181710233084', 'ID00035637202182204917484',
'ID00038637202182690843176', 'ID00042637202184406822975',
'ID00047637202184938901501', 'ID00048637202185016727717']
for patient, df in train.groupby('Patient'):
slope, intercept, _, _, _ = linregress(df['Weeks'], df['FVC'])
train.loc[train['Patient'] == patient, 'All_Data_Point_Slope'] = slope
train.loc[train['Patient'] == patient, 'Intercept'] = intercept
def plot_fvc(df, patient):
ax = df[(['Weeks', 'FVC',])].set_index('Weeks').plot(figsize=(30, 6), style=['o'], color='blue')
ax.plot(df['Weeks'],
df['All_Data_Point_Slope'] * df['Weeks'] + df['Intercept'],
label='Slope (All Data Points)', color='red', linestyle='--')
plt.tick_params(axis='x', labelsize=20)
plt.tick_params(axis='y', labelsize=20)
plt.xlabel('')
plt.ylabel('')
plt.title(f'Patient: {patient} - {df["Age"].tolist()[0]} - {df["Sex"].tolist()[0]} - {df["SmokingStatus"].tolist()[0]} ({len(df)} Measurements in {(df["Weeks"].max() - df["Weeks"].min())} Weeks Period)', size=25, pad=25)
plt.legend(prop={'size': 18})
plt.show()
for patient, df in list(train.groupby('Patient')):
if not patient in show_patients:
continue
print(f'Patient: {patient} FVC Statistical Summary\n{"-" * 58}')
print(f'Mean: {df["FVC"].mean():.6} - Median: {df["FVC"].median():.6} - Std: {df["FVC"].std():.6}')
print(f'Min: {df["FVC"].min()} - Max: {df["FVC"].max()}')
print(f'Skew: {df["FVC"].skew():.6} - Kurtosis: {df["FVC"].kurtosis():.6}\n{"-" * 58}')
print(f'Slope: {df["All_Data_Point_Slope"].values[0]:.6} - Intercept: {df["Intercept"].values[0]:.6}')
plot_fvc(df, patient)
2 Naive / non-hierarchical model¶
To highlight the effect of the hierarchical linear regression we’ll first estimate the non-hierarchical, unpooled Bayesian model from above (separate regressions). For each patient we estimate a completely separate mean (intercept). As we have no prior information on what the intercept or regressions could be, we will be using a normal distribution centered around 2500 with a wide standard-deviation 100 to describe the intercept and regressions. We’ll assume the measurements are normally distributed with noise 𝜖 on which we place a uniform distribution.
with pm.Model() as unpooled_model:
# create shared variables that can be changed later on
FVC_obs_shared = pm.Data("FVC_obs_shared", FVC_obs)
Weeks_shared = pm.Data('Weeks_shared', Weeks)
PatientID_shared = pm.Data('PatientID_shared', PatientID)
a = pm.Normal('a', 0, sigma=2500, shape=n_patients)
b = pm.Normal('b', 0, sigma=100, shape=n_patients)
# Model error
sigma = pm.HalfNormal('sigma', 150.)
FVC_est = a[PatientID_shared] + b[PatientID_shared] * Weeks_shared
# Data likelihood
FVC_like = pm.Normal('FVC_like', mu=FVC_est,
sigma=sigma, observed=FVC_obs_shared)
# Inference button (TM)!
with unpooled_model:
trace_unpooled_model = pm.sample(2000, tune=2000, target_accept=.9, init="adapt_diag")
with unpooled_model:
pm.plot_trace(trace_unpooled_model);
pred_template = []
for i in range(train['Patient'].nunique()):
df = pd.DataFrame(columns=['PatientID', 'Weeks'])
df['Weeks'] = np.arange(-12, 134)
df['PatientID'] = i
pred_template.append(df)
pred_template = pd.concat(pred_template, ignore_index=True)
with unpooled_model:
pm.set_data({
"PatientID_shared": pred_template['PatientID'].values.astype(int),
"Weeks_shared": pred_template['Weeks'].values.astype(int),
"FVC_obs_shared": np.zeros(len(pred_template)).astype(int),
})
post_pred = pm.sample_posterior_predictive(trace_unpooled_model)
df = pd.DataFrame(columns=['Patient', 'Weeks', 'FVC_pred', 'sigma'])
df['Patient'] = le_id.inverse_transform(pred_template['PatientID'])
df['Weeks'] = pred_template['Weeks']
df['FVC_pred'] = post_pred['FVC_like'].T.mean(axis=1)
df['sigma'] = post_pred['FVC_like'].T.std(axis=1)
df['FVC_inf'] = df['FVC_pred'] - df['sigma']
df['FVC_sup'] = df['FVC_pred'] + df['sigma']
df = pd.merge(df, train[['Patient', 'Weeks', 'FVC']], how='left', on=['Patient', 'Weeks'])
df = df.rename(columns={'FVC': 'FVC_true'})
df.head()
def chart(patient_id, ax):
data = df[df['Patient'] == patient_id]
x = data['Weeks']
ax.set_title(patient_id)
ax.plot(x, data['FVC_true'], 'o')
ax.plot(x, data['FVC_pred'])
ax = sns.regplot(x, data['FVC_true'], ax=ax, ci=None,
line_kws={'color':'red'})
ax.fill_between(x, data["FVC_inf"], data["FVC_sup"],
alpha=0.5, color='#ffcd3c')
ax.set_ylabel('FVC')
f, axes = plt.subplots(2, 3, figsize=(15, 10))
chart('ID00007637202177411956430', axes[0, 0])
chart('ID00009637202177434476278', axes[0, 1])
chart('ID00011637202177653955184', axes[0, 2])
chart('ID00419637202311204720264', axes[1, 0])
chart('ID00421637202311550012437', axes[1, 1])
chart('ID00422637202311677017371', axes[1, 2])
3. Model A: Bayesian Hierarchical Linear Regression with Partial Pooling
Hierarchical modeling allows the best of both worlds by modeling subjects’ similarities but also allowing estimiation of individual parameters.
Our first model (A) is the simplest possible Bayesian Hierarchical Linear Regression model. It assumes every patient has a personalized FVC decline curve, with a single intercept ($\alpha$) and slope ($\beta$).
Actually the simplest possible linear regression, not hierarchical, would assume all FVC decline curves have the same $\alpha$ and $\beta$. That’s the pooled model. In the other extreme, we could assume a model where each patient has a personalized FVC decline curve, and these curves are completely unrelated. That’s the unpooled model, where each patient has completely separate regressions.
Here, we will use the middle ground: Partial pooling. Specifically, we will assume that while $\alpha$’s and $\beta$’s are different for each patient as in the unpooled case, the coefficients all share similarity. We can model this by assuming that each individual coefficient comes from a common group distribution. For more details about these 3 different ways of modelling, check GLM: Hierarchical Linear Regression great tutorial. The graphic model below represents this model:

Mathematically, the model is described by the following equations:
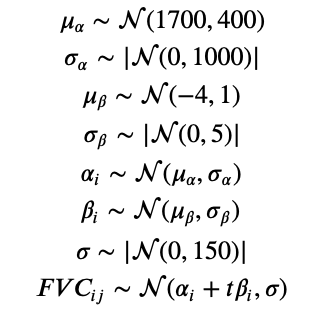
where t is the time in weeks. You might ask why we have chosen these specific priors. We did some iterations, at first with pretty vague/uninformative priors. After observing the first results, we converged to these distributions described above. Although PyMC3 samplers can work pretty well with uninformative priors, other PPLs such as Pyro requires more specific priors (otherwise their samplers take a really long time to converge).
Implementing it in PyMC3 is very straightforward:
exclude_test_patient_data_from_trainset = True
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
if exclude_test_patient_data_from_trainset:
train = train[~train['Patient'].isin(test['Patient'].unique())]
train = pd.concat([train, test], axis=0, ignore_index=True)\
.drop_duplicates()
le_id = LabelEncoder()
train['PatientID'] = le_id.fit_transform(train['Patient'])
train.head()
n_patients = train['Patient'].nunique()
FVC_obs = train['FVC'].values
Weeks = train['Weeks'].values
PatientID = train['PatientID'].values
with pm.Model() as model_a:
# create shared variables that can be changed later on
FVC_obs_shared = pm.Data("FVC_obs_shared", FVC_obs)
Weeks_shared = pm.Data('Weeks_shared', Weeks)
PatientID_shared = pm.Data('PatientID_shared', PatientID)
mu_a = pm.Normal('mu_a', mu=1700., sigma=400)
sigma_a = pm.HalfNormal('sigma_a', 1000.)
mu_b = pm.Normal('mu_b', mu=-4., sigma=1)
sigma_b = pm.HalfNormal('sigma_b', 5.)
a = pm.Normal('a', mu=mu_a, sigma=sigma_a, shape=n_patients)
b = pm.Normal('b', mu=mu_b, sigma=sigma_b, shape=n_patients)
# Model error
sigma = pm.HalfNormal('sigma', 150.)
FVC_est = a[PatientID_shared] + b[PatientID_shared] * Weeks_shared
# Data likelihood
FVC_like = pm.Normal('FVC_like', mu=FVC_est,
sigma=sigma, observed=FVC_obs_shared)
4. Fiting model A
Just press the inference button (TM)! :)
# Inference button (TM)!
with model_a:
trace_a = pm.sample(2000, tune=2000, target_accept=.9, init="adapt_diag")
5. Checking model A
5.1. Inspecting the learned parameters
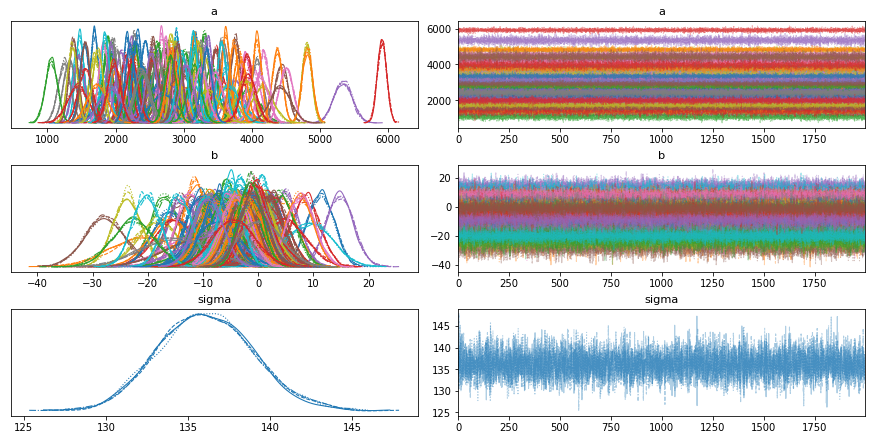
First, let’s inspect the parameters learned:
with model_a:
pm.plot_trace(trace_a);
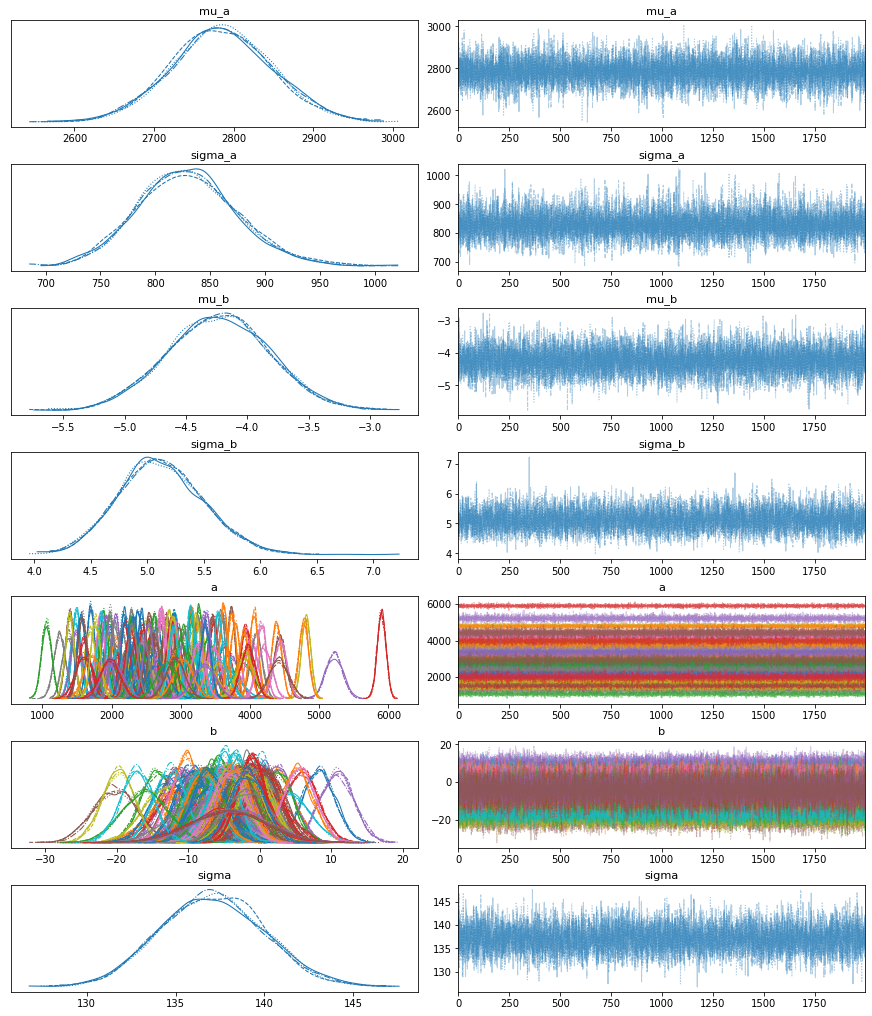
Great! It looks like our model learned different $\alpha$’s and $\beta$’s for each patient, pooled from the same source distribution.
5.2. Visualizing FVC decline curves for some patients
Now, let’s visually inspect FVC decline curves predicted by our model. We will completely fill in the FVC table, predicting all missing values. The first step is to create a table to fill:
pred_template = []
for i in range(train['Patient'].nunique()):
df = pd.DataFrame(columns=['PatientID', 'Weeks'])
df['Weeks'] = np.arange(-12, 134)
df['PatientID'] = i
pred_template.append(df)
pred_template = pd.concat(pred_template, ignore_index=True)
Now, let’s generate all predictions and fill in the table:
with model_a:
pm.set_data({
"PatientID_shared": pred_template['PatientID'].values.astype(int),
"Weeks_shared": pred_template['Weeks'].values.astype(int),
"FVC_obs_shared": np.zeros(len(pred_template)).astype(int),
})
post_pred = pm.sample_posterior_predictive(trace_a)
df = pd.DataFrame(columns=['Patient', 'Weeks', 'FVC_pred', 'sigma'])
df['Patient'] = le_id.inverse_transform(pred_template['PatientID'])
df['Weeks'] = pred_template['Weeks']
df['FVC_pred'] = post_pred['FVC_like'].T.mean(axis=1)
df['sigma'] = post_pred['FVC_like'].T.std(axis=1)
df['FVC_inf'] = df['FVC_pred'] - df['sigma']
df['FVC_sup'] = df['FVC_pred'] + df['sigma']
df = pd.merge(df, train[['Patient', 'Weeks', 'FVC']], how='left', on=['Patient', 'Weeks'])
df = df.rename(columns={'FVC': 'FVC_true'})
df.head()
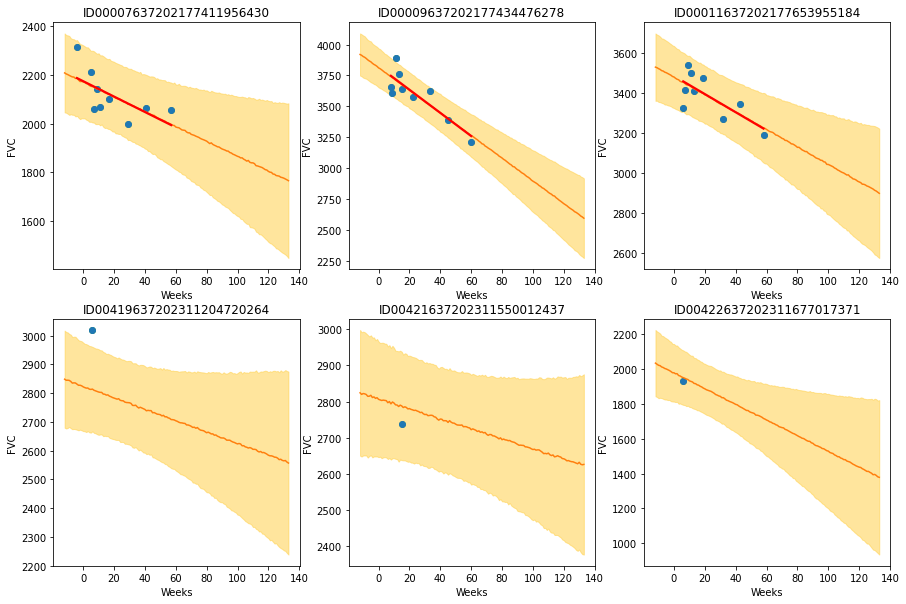
Now, let’s visualize the predictions for 6 patients:
- In the first row, we can see predictions for 3 patients for which our model had several points to learn personalized $\alpha$’s and $\beta$’s
- In the second row, we can see predictions for 3 patients for which our model had only a single point to learn personalized $\alpha$’s and $\beta$’s
def chart(patient_id, ax):
data = df[df['Patient'] == patient_id]
x = data['Weeks']
ax.set_title(patient_id)
ax.plot(x, data['FVC_true'], 'o')
ax.plot(x, data['FVC_pred'])
ax = sns.regplot(x, data['FVC_true'], ax=ax, ci=None,
line_kws={'color':'red'})
ax.fill_between(x, data["FVC_inf"], data["FVC_sup"],
alpha=0.5, color='#ffcd3c')
ax.set_ylabel('FVC')
f, axes = plt.subplots(2, 3, figsize=(15, 10))
chart('ID00007637202177411956430', axes[0, 0])
chart('ID00009637202177434476278', axes[0, 1])
chart('ID00011637202177653955184', axes[0, 2])
chart('ID00419637202311204720264', axes[1, 0])
chart('ID00421637202311550012437', axes[1, 1])
chart('ID00422637202311677017371', axes[1, 2])
The results are exactly what we expected to see! Highlight observations:
- The model adequately learned Bayesian Linear Regressions! The orange line (learned predicted FVC mean) is very inline with the red line (deterministic linear regression). But most important: it learned to predict uncertainty, showed in the light orange region (one sigma above and below the mean FVC line)
- In the first row, where the model had several points for each patient, we can see the model predicts a higher uncertainty where the data points are more disperse (1st and 3rd patients). Conversely, where the points are more grouped together (2nd patient, first row), the model predicts a higher confidence (narrower light orange region)
- In the 2nd row, we can see our model does a good job even when we supply it with only a single data point per patient to use as base to make inferences!
- Comparing the first 3 patients in the first row with the last 3 patients on the 2nd row, we can see that our model correctly estimates a higher confidence for the first 3 patients, for which it had more data points to make inferences!
- Finally, in all 6 patients, we can see that the uncertainty grows as the look more into the future: the light orange region widens as the # of weeks grow! That makes a lot of sense!
5.3. Computing the modified Laplace Log Likelihood and RMSE
These are straightforward to compute:
# Add the test data points back to calculate the metrics
tr = pd.read_csv('train.csv')
df = pd.merge(df, tr[['Patient', 'Weeks', 'FVC']], how='left', on=['Patient', 'Weeks'])
use_only_last_3_measures = True
if use_only_last_3_measures:
y = df.dropna().groupby('Patient').tail(3)
else:
y = df.dropna()
rmse = ((y['FVC_pred'] - y['FVC']) ** 2).mean() ** (1/2)
print(f'RMSE: {rmse:.1f} ml')
sigma_c = y['sigma'].values
sigma_c[sigma_c < 70] = 70
delta = (y['FVC_pred'] - y['FVC']).abs()
delta[delta > 1000] = 1000
lll = - np.sqrt(2) * delta / sigma_c - np.log(np.sqrt(2) * sigma_c)
print(f'Laplace Log Likelihood: {lll.mean():.4f}')
These look like very encouraging numbers, especially taking into consideration that we only used 3 columns: FVC, weeks and Patient ID, discarding all the rest. Now, let’s go to the 2nd objective.
6. Extending the model to use more tabular data
We will implement very few changes to make our model use all possible tabular data. The first is simply one-hot encode the categorical features Sex and SmokingStatus. In order to avoid multicollinearity issues, we will drop the last column after transforming both. (For more about multicollinearity issues, check here). The second is adding percent at baseline feature.
train['Male'] = train['Sex'].apply(lambda x: 1 if x == 'Male' else 0)
train["SmokingStatus"] = train["SmokingStatus"].astype(
pd.CategoricalDtype(['Ex-smoker', 'Never smoked', 'Currently smokes'])
)
aux = pd.get_dummies(train["SmokingStatus"], prefix='ss')
aux.columns = ['ExSmoker', 'NeverSmoked', 'CurrentlySmokes']
train['ExSmoker'] = aux['ExSmoker']
train['CurrentlySmokes'] = aux['CurrentlySmokes']
aux = train[['Patient', 'Weeks']].sort_values(by=['Patient', 'Weeks'])
aux = train.groupby('Patient').head(1)
train = pd.merge(train, aux[['Patient']], how='left', on='Patient')
And that’s all there is to it.
7. Model B: Hierarchical Model with Partial Pooling using more tabular data
The model is essentially the same as model A. There is, though, a slight change. The equation that predicts the FVC is changed to:
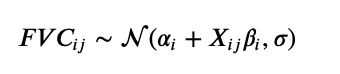
Now, multiplying $\beta_i$ we have $X_{ij}$ instead of t. $X_{ij}$ is a vector of the patient i at timestep j that contains:
- Male binary code from patient i at timestep j (which is constant at all timesteps)
- Ex-smoker binary code from patient i at timestep j (which is constant at all timesteps)
- Currently-smokes binary code from patient i at timestep j (which is constant at all timesteps)
- Percent from patient i at baseline moment
- The week (timestep j)
Some good questions and our best answers:
- Why aren’t you including age? Empirically, when we add age to the features, it significantly degrades the model performance. Don’t know exactly why this happens. We hypothesize that this is due to multicollinearity. Anyways, in a model trained to predict personalized curves of FVC decline, in which we inform the Patient ID, in theory everything that qualifies the patient should be already encoded in its ID.
- Why are you considering Percent at baseline moment only, discarding the other values? That’s a very good question :) The percent feature varies in time, and it is strongly correlated with FVC (the variable we are interested in predicting). However, at inference time, we don’t have percent feature in every week from [-12, 133]; we only have the percent at baseline moment. At inference time, if we consider percent flat from week -12 to week 133 (as we saw in some notebooks), that would be conceptually wrong IMHO. The only number we have is the percent at baseline moment. So, that’s the number we feed our model.
n_patients = train['Patient'].nunique()
FVC_obs = train['FVC'].values
X = train[['Weeks', 'Male', 'ExSmoker', 'CurrentlySmokes']].values
PatientID = train['PatientID'].values
with pm.Model() as model_b:
# create shared variables that can be changed later on
FVC_obs_shared = pm.Data("FVC_obs_shared", FVC_obs)
X_shared = pm.Data('X_shared', X)
PatientID_shared = pm.Data('PatientID_shared', PatientID)
mu_a = pm.Normal('mu_a', mu=1700, sigma=400)
sigma_a = pm.HalfNormal('sigma_a', 1000.)
mu_b = pm.Normal('mu_b', mu=-4., sigma=1., shape=X.shape[1])
sigma_b = pm.HalfNormal('sigma_b', 5.)
a = pm.Normal('a', mu=mu_a, sigma=sigma_a, shape=n_patients)
b = pm.Normal('b', mu=mu_b, sigma=sigma_b, shape=(n_patients, X.shape[1]))
# Model error
sigma = pm.HalfNormal('sigma', 150.)
FVC_est = a[PatientID_shared] + (b[PatientID_shared] * X_shared).sum(axis=1)
# Data likelihood
FVC_like = pm.Normal('FVC_like', mu=FVC_est,
sigma=sigma, observed=FVC_obs_shared)
8. Fiting model B
Just press the inference button (TM)! :)
# Inference button (TM)!
with model_b:
trace_b = pm.sample(2000, tune=2000, target_accept=.9, init="adapt_diag")
9. Checking model B
9.1. Inspecting the learned parameters
First, let’s inspect the parameters learned:
with model_b:
pm.plot_trace(trace_b);
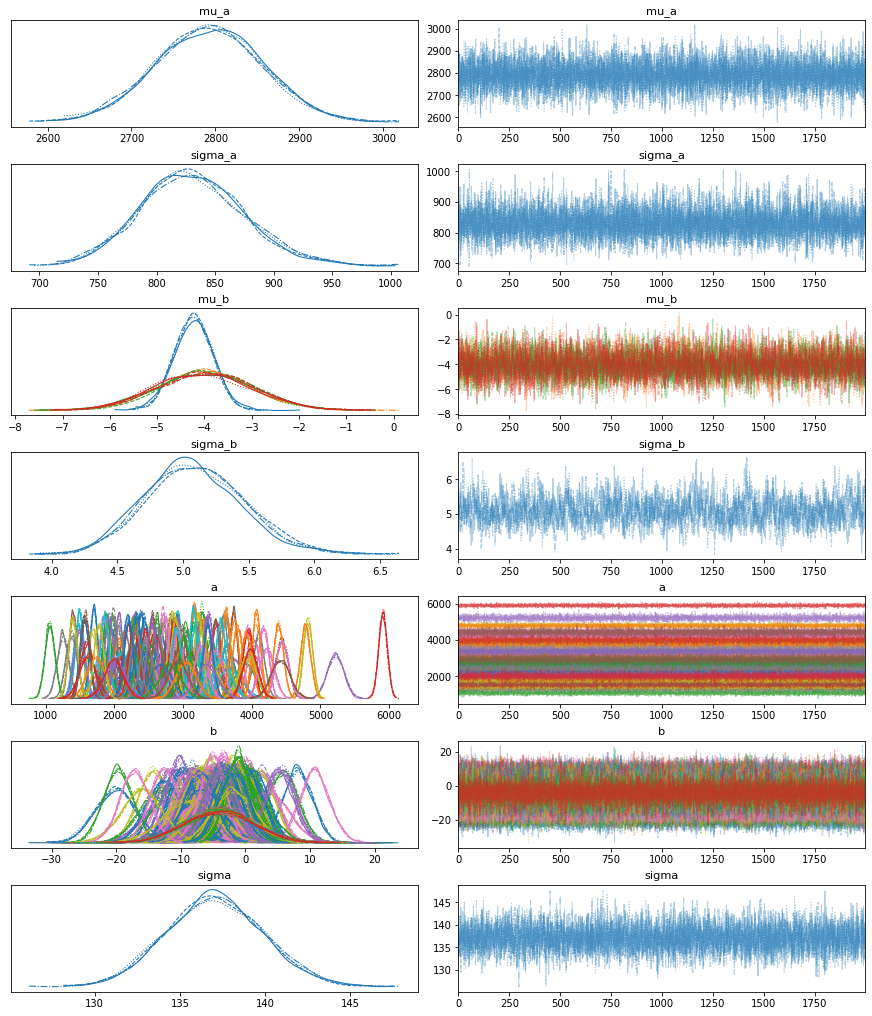
Great! Again, it looks like our model learned different $\alpha$’s and $\beta$’s for each patient, pooled from the same source distribution. Note: this model is unstable, and sometimes do not converge.
9.2. Visualizing FVC decline curves for some patients
Now, let’s visually inspect FVC decline curves predicted by our model. We will completely fill in the FVC table, predicting all missing values. The first step is to create a table to fill:
aux = train.groupby('Patient').first().reset_index()
pred_template = []
for i in range(train['Patient'].nunique()):
df = pd.DataFrame(columns=['PatientID', 'Weeks'])
df['Weeks'] = np.arange(-12, 134)
df['PatientID'] = i
df['Male'] = aux[aux['PatientID'] == i]['Male'].values[0]
df['ExSmoker'] = aux[aux['PatientID'] == i]['ExSmoker'].values[0]
df['CurrentlySmokes'] = aux[aux['PatientID'] == i]['CurrentlySmokes'].values[0]
pred_template.append(df)
pred_template = pd.concat(pred_template, ignore_index=True)
Now, let’s fill the table:
with model_b:
pm.set_data({
"PatientID_shared": pred_template['PatientID'].values.astype(int),
"X_shared": pred_template[['Weeks', 'Male', 'ExSmoker',
'CurrentlySmokes']].values.astype(int),
"FVC_obs_shared": np.zeros(len(pred_template)).astype(int),
})
post_pred = pm.sample_posterior_predictive(trace_b)
df = pd.DataFrame(columns=['Patient', 'Weeks', 'FVC_pred', 'sigma'])
df['Patient'] = le_id.inverse_transform(pred_template['PatientID'])
df['Weeks'] = pred_template['Weeks']
df['FVC_pred'] = post_pred['FVC_like'].T.mean(axis=1)
df['sigma'] = post_pred['FVC_like'].T.std(axis=1)
df['FVC_inf'] = df['FVC_pred'] - df['sigma']
df['FVC_sup'] = df['FVC_pred'] + df['sigma']
df = pd.merge(df, train[['Patient', 'Weeks', 'FVC']], how='left', on=['Patient', 'Weeks'])
df = df.rename(columns={'FVC': 'FVC_true'})
df.head()
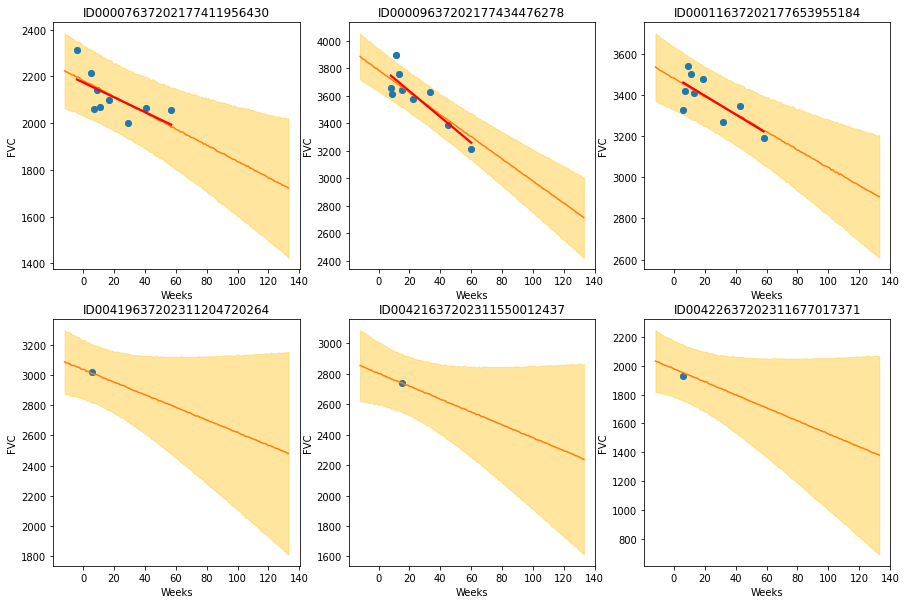
And finally, let’s visualize again 6 patients, the same 6 we saw with Model A:
def chart(patient_id, ax):
data = df[df['Patient'] == patient_id]
x = data['Weeks']
ax.set_title(patient_id)
ax.plot(x, data['FVC_true'], 'o')
ax.plot(x, data['FVC_pred'])
ax = sns.regplot(x, data['FVC_true'], ax=ax, ci=None,
line_kws={'color':'red'})
ax.fill_between(x, data["FVC_inf"], data["FVC_sup"],
alpha=0.5, color='#ffcd3c')
ax.set_ylabel('FVC')
f, axes = plt.subplots(2, 3, figsize=(15, 10))
chart('ID00007637202177411956430', axes[0, 0])
chart('ID00009637202177434476278', axes[0, 1])
chart('ID00011637202177653955184', axes[0, 2])
chart('ID00419637202311204720264', axes[1, 0])
chart('ID00421637202311550012437', axes[1, 1])
chart('ID00422637202311677017371', axes[1, 2])
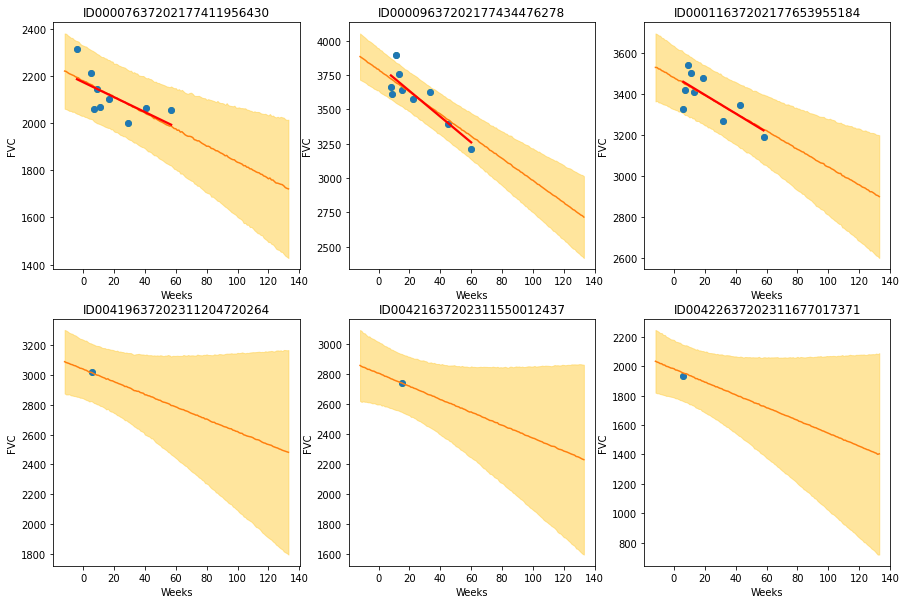
It looks like Model B generates the same results as Model A. Note: this model is unstable, and sometimes do not converge.
9.3. Computing the modified Laplace Log Likelihood and RMSE
Finally, let’s check the metrics for model B:
# Add the test data points back to calculate the metrics
tr = pd.read_csv('train.csv')
df = pd.merge(df, tr[['Patient', 'Weeks', 'FVC']], how='left', on=['Patient', 'Weeks'])
use_only_last_3_measures = True
if use_only_last_3_measures:
y = df.dropna().groupby('Patient').tail(3)
else:
y = df.dropna()
rmse = ((y['FVC_pred'] - y['FVC_true']) ** 2).mean() ** (1/2)
print(f'RMSE: {rmse:.1f} ml')
sigma_c = y['sigma'].values
sigma_c[sigma_c < 70] = 70
delta = (y['FVC_pred'] - y['FVC_true']).abs()
delta[delta > 1000] = 1000
lll = - np.sqrt(2) * delta / sigma_c - np.log(np.sqrt(2) * sigma_c)
print(f'Laplace Log Likelihood: {lll.mean():.4f}')
Again, we see good encouraging numbers (Note: this model is unstable, and sometimes do not converge.). However, these are remarkably close to the numbers we obtained when we used only FVC, weeks and Patient ID - actually a little bit worse. Why is that the case? Why aren’t these new features helping the model? We discuss this question and other learnings in the next section.
10. Discussion
Our first objective was to build a stable error-free simplest possible Bayesian Hierarchical Linear Regression model. We achieved it, implementing a model with partial pooling, where each patient has a personalized FVC decline curve with personalized parameters, but all these parameters share similarities, being drawn from the same shared distributions.
The results observed from the experiment with model A met our expectations. The model adequately learned not only to predict good FVC declines (low RMSE) but also learned to properly gauge confidence (low Laplace Log Likelihood). We saw that our model effectively made predictions even in the challenging situation where it had only a single FVC measure to base its future FVC forecasts. We visually saw higher predicted confidence when the FVC data points were grouped together in a more clear line, and a lower predicted confidence when the FVC measurements were more disperse. Our model was also able to properly predict decreasing confidence as we looked more and more into the future.
While experimenting with model B, our 2nd objective, we had to deal with multicollinearity, a common problem of linear regression models in high dimensions. After dropping some features to avoid it, we were able to observe the results, which were very similar than the ones obtained with model A. So, with this modelling, new features did not improve our predictive error.
We hypothesise that this happens because all the information that qualifies a patient is already encoded in the Patient ID. Once we feed the model with this information, nothing else matters: it is the maximum of personalisation. Any other feature that groups patients are, by definition, more general than the Patient ID (the maximum of personalisation). This refers back to the original idea that sparked this line of thought: collaborative filtering. There are basically 2 approaches to mass-customize recommendations (adopted by giants such as Amazon, Netflix, Facebook, etc): collaborative filtering and content-base filtering. The former learns to group similar users based on their ratings (nothing else matters), while the latter recommends based on user & item’s features. So, the fact that model B produce similar scores of model A, even with more features, is consistent with the adopted approach.
Maybe with a larger base of patients, more features would help the model to group them together. However, only 176 patients is too few.
Occam’s Razor
Now, let’s re-train the model using all data, and submit a solution. But which model, A or B?
The principle of simplicity in scientific models and theories is commonly called Ockham’s razor, or Occham’s razor. It is popularly attributed to 1400s English friar and philosopher William of Ockham, also known as William of Occham. The razor alludes to the shaving away of unneeded detail. A common paraphrase of Ockham’s principle, originally written in Latin, is “All things being equal, the simplest solution tends to be the best one.”
This is such a popular concept that we will leave Lisa Simpson’s explanation of Occam’s Razor principle as our final remark :)
11. Final submission
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
train = pd.concat([train, test], axis=0, ignore_index=True)\
.drop_duplicates()
le_id = LabelEncoder()
train['PatientID'] = le_id.fit_transform(train['Patient'])
n_patients = train['Patient'].nunique()
FVC_obs = train['FVC'].values
Weeks = train['Weeks'].values
PatientID = train['PatientID'].values
with pm.Model() as model_a:
# create shared variables that can be changed later on
FVC_obs_shared = pm.Data("FVC_obs_shared", FVC_obs)
Weeks_shared = pm.Data('Weeks_shared', Weeks)
PatientID_shared = pm.Data('PatientID_shared', PatientID)
mu_a = pm.Normal('mu_a', mu=1700., sigma=400)
sigma_a = pm.HalfNormal('sigma_a', 1000.)
mu_b = pm.Normal('mu_b', mu=-4., sigma=1)
sigma_b = pm.HalfNormal('sigma_b', 5.)
a = pm.Normal('a', mu=mu_a, sigma=sigma_a, shape=n_patients)
b = pm.Normal('b', mu=mu_b, sigma=sigma_b, shape=n_patients)
# Model error
sigma = pm.HalfNormal('sigma', 150.)
FVC_est = a[PatientID_shared] + b[PatientID_shared] * Weeks_shared
# Data likelihood
FVC_like = pm.Normal('FVC_like', mu=FVC_est,
sigma=sigma, observed=FVC_obs_shared)
# Fitting the model
trace_a = pm.sample(2000, tune=2000, target_accept=.9, init="adapt_diag")
pred_template = []
for p in test['Patient'].unique():
df = pd.DataFrame(columns=['PatientID', 'Weeks'])
df['Weeks'] = np.arange(-12, 134)
df['Patient'] = p
pred_template.append(df)
pred_template = pd.concat(pred_template, ignore_index=True)
pred_template['PatientID'] = le_id.transform(pred_template['Patient'])
with model_a:
pm.set_data({
"PatientID_shared": pred_template['PatientID'].values.astype(int),
"Weeks_shared": pred_template['Weeks'].values.astype(int),
"FVC_obs_shared": np.zeros(len(pred_template)).astype(int),
})
post_pred = pm.sample_posterior_predictive(trace_a)
df = pd.DataFrame(columns=['Patient', 'Weeks', 'Patient_Week', 'FVC', 'Confidence'])
df['Patient'] = pred_template['Patient']
df['Weeks'] = pred_template['Weeks']
df['Patient_Week'] = df['Patient'] + '_' + df['Weeks'].astype(str)
df['FVC'] = post_pred['FVC_like'].T.mean(axis=1)
df['Confidence'] = post_pred['FVC_like'].T.std(axis=1)
final = df[['Patient_Week', 'FVC', 'Confidence']]
final.to_csv('submission.csv', index=False)